PivotXL provides your team with sophisticated tools for collaboration, automation, and systematizing your FP&A processes, converting each challenge into a chance for growth and success
Budgeting and MIS software for mid-sized Companies
End the spreadsheet struggle, CSV chaos, and the search for outdated files. Say goodbye to cumbersome, outdated software. Experience the power of modern FP&A software designed for small and mid-tier companies.
Secure Cloud
Our application is constructed atop SOC2-approved data centers, bolstered by multiple security controls at the application level to ensure enhanced security.
SaaS Model
You won't need to worry about internal hosting or IT management. Finance teams can fully manage the application.
Built on top of Excel
Our platform is built on the familiar foundation of Excel, allowing you to leverage your existing modeling skills, while providing robust data guardrails for enhanced reliability and security
our features
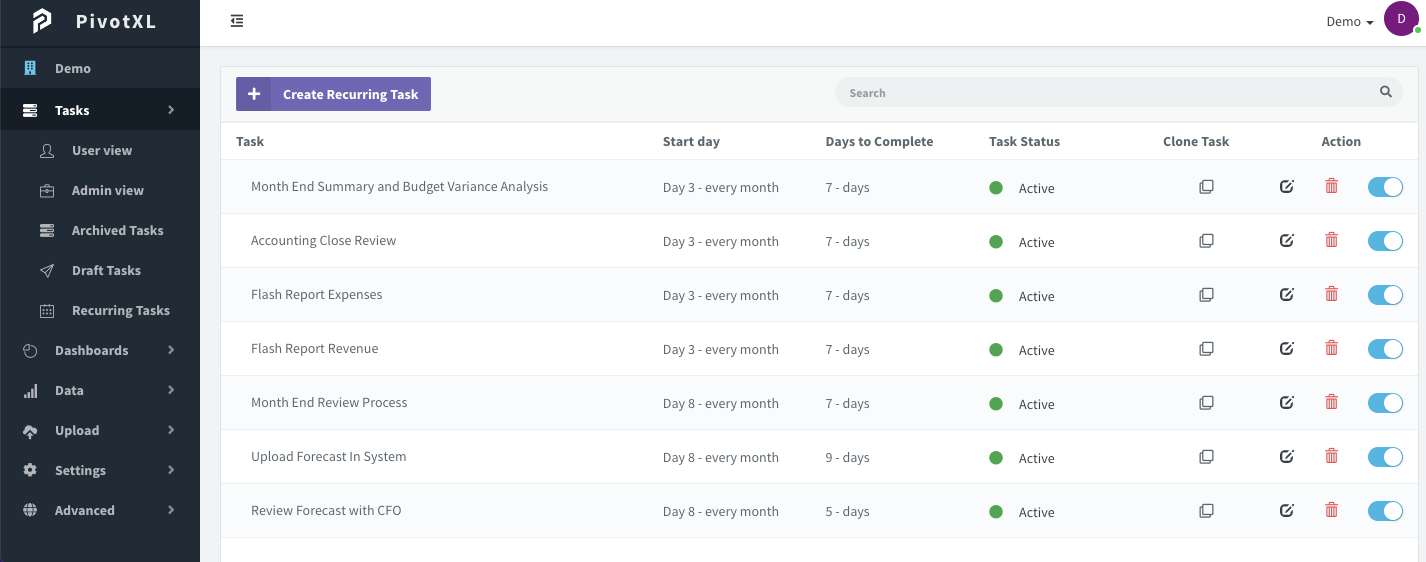
Comprehensive Task
Management
Task Management Essentials
Our system is equipped with reviewers, approvers, due dates, comments, and support for essential documents
Enhanced Systematization
Incorporates draft and recurring tasks to streamline and systematize key processes effectively.
Continuous Updates & Accessibility
Ensures ongoing accountability with regular updates on task progress and approvals, while keeping all key documents and insights readily accessible.
Cube Data Storage
User-Friendly Data Interaction
Unlike complex SQL databases, our Cube Data Storage offers a simpler format that allows easy slicing and dicing of data, making it particularly user-friendly for finance professionals.
Customizable for Various Needs
The storage system is highly adaptable to diverse business scenarios, enabling easy customization for different business
Flexible Capabilities
Paired with customizable groupings and roll-ups, our Cube Data Storage facilitates the creation of various financial statements and reports, including multiple types of P&L statements, balance sheets, and more
Excel and Web Dashboards
Excel-Integrated Reporting
Leverage deep Excel integration for versatile report creation and utilize Excel's robust calculation engine for forecasting models.
Collaborative Web Dashboards
Design and share dashboards with ease, enhancing teamwork and communication.
Accessible Sharing
Tailor dashboard sharing to ensure the right people have access to critical information and insights.
Achieve a 50% reduction in budget cycle
duration for more efficient financial planning.
Enhanced Systematization
Incorporates draft and recurring tasks to streamline and systematize key processes effectively.
Continuous Updates & Accessibility
Ensures ongoing accountability with regular updates on task progress and approvals, while keeping all key documents and insights readily accessible.
Simplify Reporting and Variance
Systematic Variance Analysis
Conduct detailed variance analyses across different departments, uncovering the '5 Whys' to facilitate quicker course correction and informed decision-making.
Accelerated Course Correction
Implement faster adjustments and improvements in response to financial insights and trends, enhancing overall business agility
Advanced Reporting Capabilities
Generate a variety of reports, including advanced analyses like product-wise profitability, to gain deeper insights and drive strategic business decisions.
Enhance Forecasting
Excel Model Integration
Retain your existing Excel models while adding enhanced data integrity, enabling the creation of accurate rolling forecasts.
Comprehensive Forecast Aggregation
Merge sub-level forecasts with automatic roll-ups, facilitating the creation of diverse and detailed forecasts.
Scenario Analysis
Develop multiple forecasting scenarios and conduct sensitivity analysis for comprehensive comparison and strategic planning.
Manager of Finance and Business
Analytics, Young Brothers Limited
We had purchased another on-premise system five years back that was not being actively used. PivotXL allowed us to use our existing Excel templates and slowly transition into a cloud system.
Melina Fleming
Finance Manager, Young
Brothers Limited
I have been using PivotXL for 3 years now. It’s user auditability, validation reports and streamlined workflow has significantly increased our budgeting process and accuracy of output numbers.
Case Study
PivotXL transformed Young Brothers’ budgeting process into a more efficient, collaborative, and data-driven operation. This strategic partnership enabled their leadership to focus on driving business growth and making informed decisions, setting the stage for impressive results and long-term success in their financial management.
Explore our comprehensive library of training videos for PivotXL. Whether you’re new to the platform or looking to master advanced features, our video tutorials provide step-by-step guidance to help you maximize your PivotXL experience. Learn at your own pace and harness the full potential of our powerful financial planning and analysis tool.
Dive into our extensive collection of informative articles covering all aspects of PivotXL. From best practices to industry insights, our articles are designed to empower you with knowledge and expertise. Whether you’re a beginner or a seasoned user, our articles provide valuable insights to enhance your proficiency in using PivotXL for financial planning and analysis.
Join our engaging webinars to stay at the forefront of financial planning and analysis with PivotXL. Our expert-led sessions cover a wide range of topics, from product updates to industry trends. Whether you’re seeking in-depth knowledge or practical tips, our webinars offer valuable insights to help you excel in your financial roles. Don’t miss the opportunity to learn, connect, and grow with PivotXL webinars.